RAGu - фабрика ИИ агентов
Общее описание
Суть RAG (Retrieval-Augmented Generation): Это технология, которая сочетает в себе поиск информации из ваших собственных баз знаний с генеративными способностями больших языковых моделей (LLM). Вместо того чтобы полагаться только на внутренние знания модели, RAG сначала находит нужные данные в ваших документах, а затем использует их для формирования точного и контекстуально обоснованного ответа.
Основные преимущества:
- Точность: Значительно снижает количество “галлюцинаций” (выдуманных фактов) у LLM.
- Контекстуализация: Ответы основаны на предоставленных вами документах, а не на общих знаниях модели.
- Безопасность: Данные остаются под вашим контролем (on-premise или в вашем облаке).
- Верифицируемость: Каждый ответ можно проверить, так как система показывает исходные фрагменты документов, на основе которых был сгенерирован ответ.
Система обладает продвинутыми средствами обработки документов — глубокое понимание документов за счет использования продвинутых методов распознавания изображений на базе VLM и передовых методов разбиения текста (chunking) с последующим извлечением наиболее релевантных фрагментов для предоставления языковой модели точного контекста.
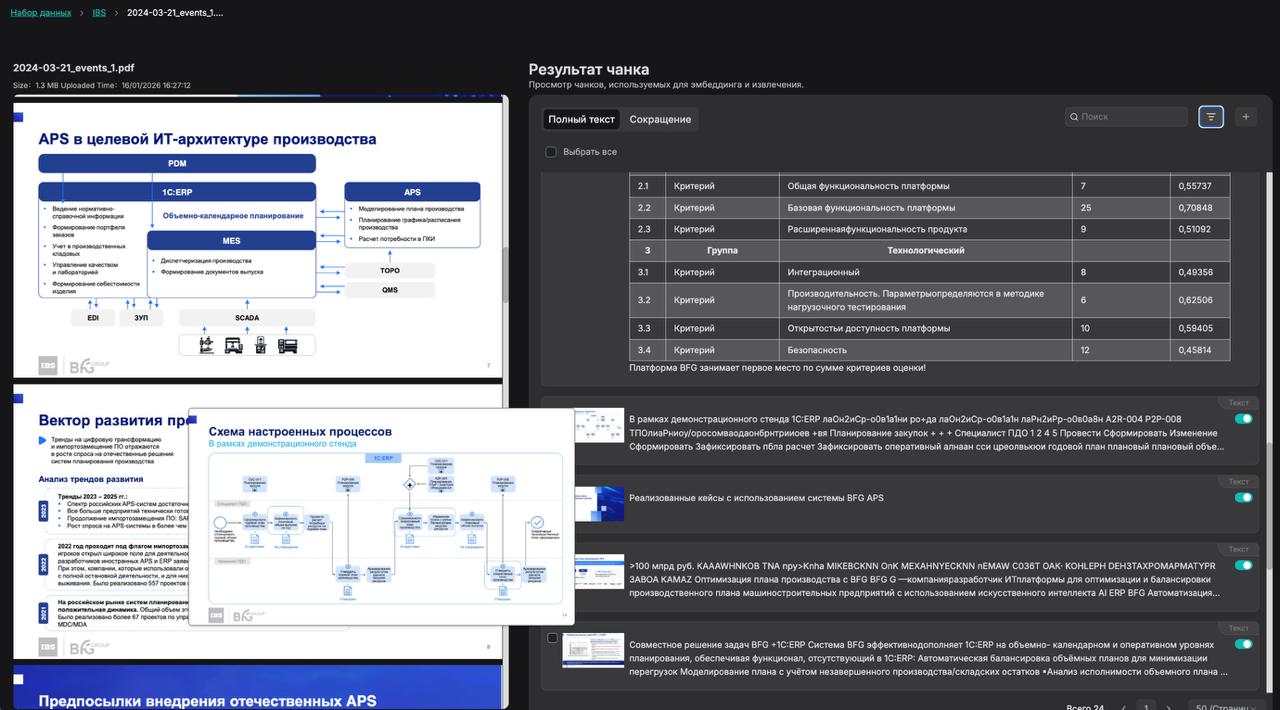
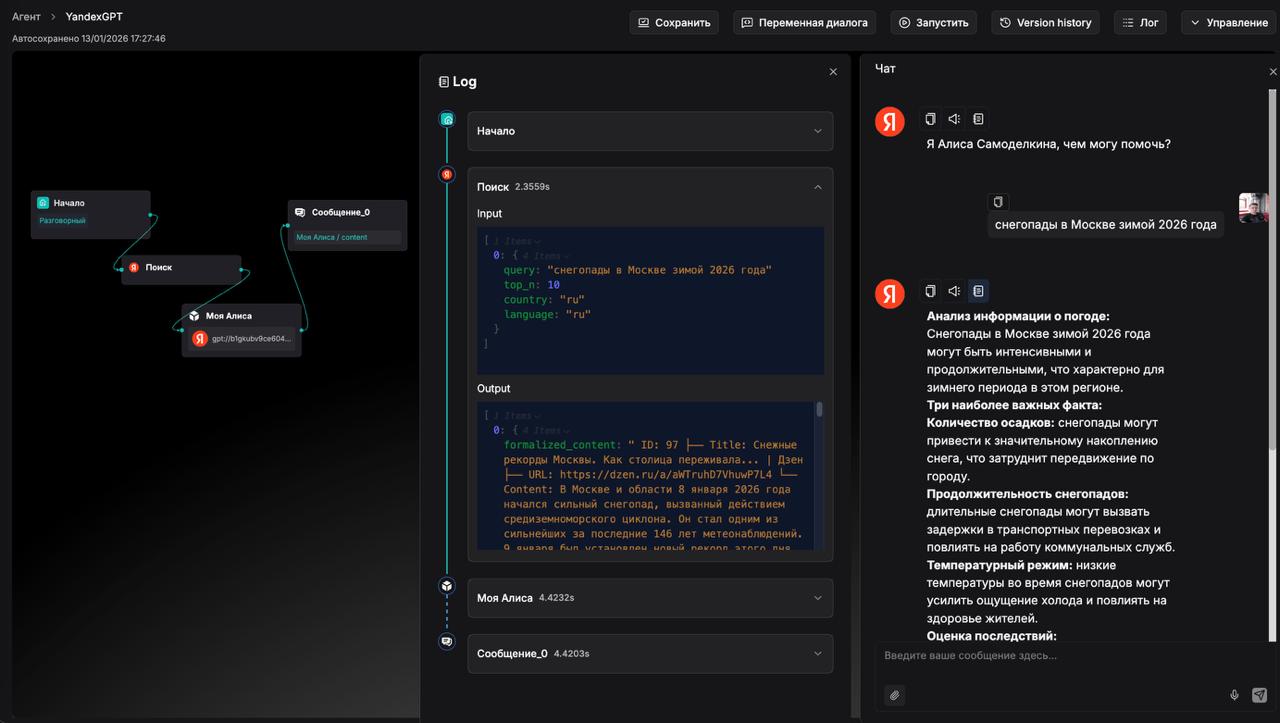
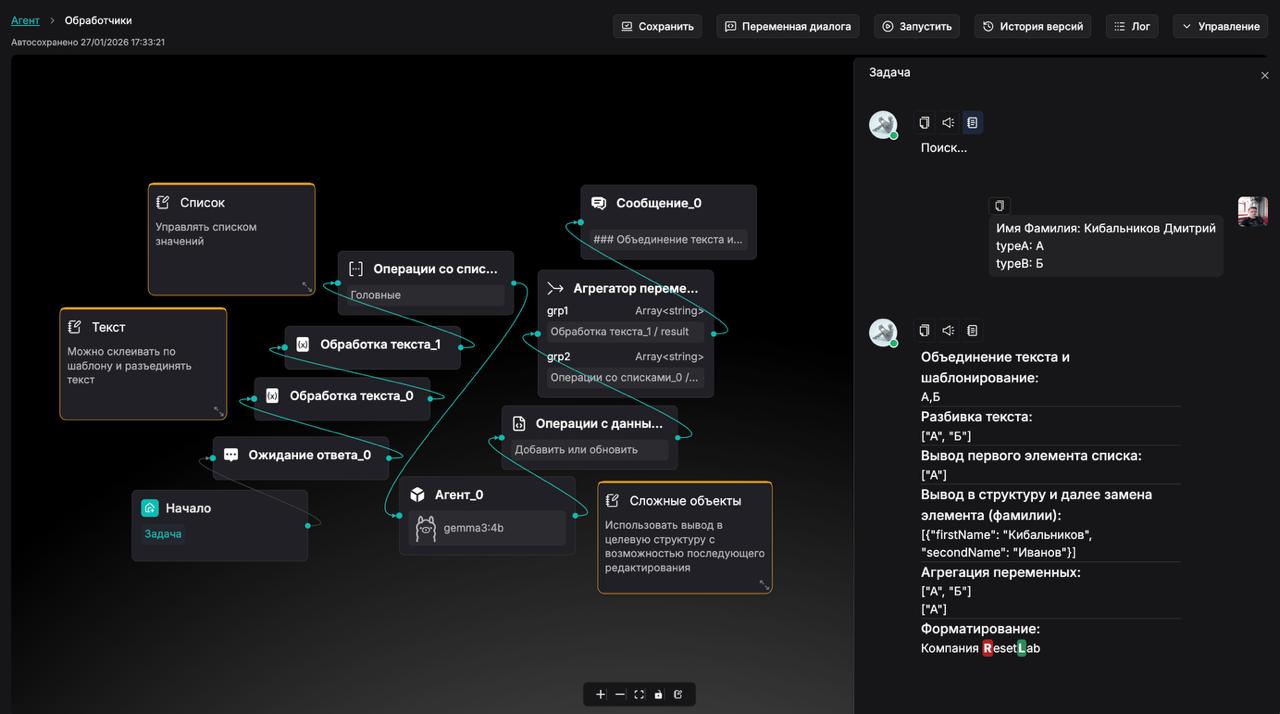
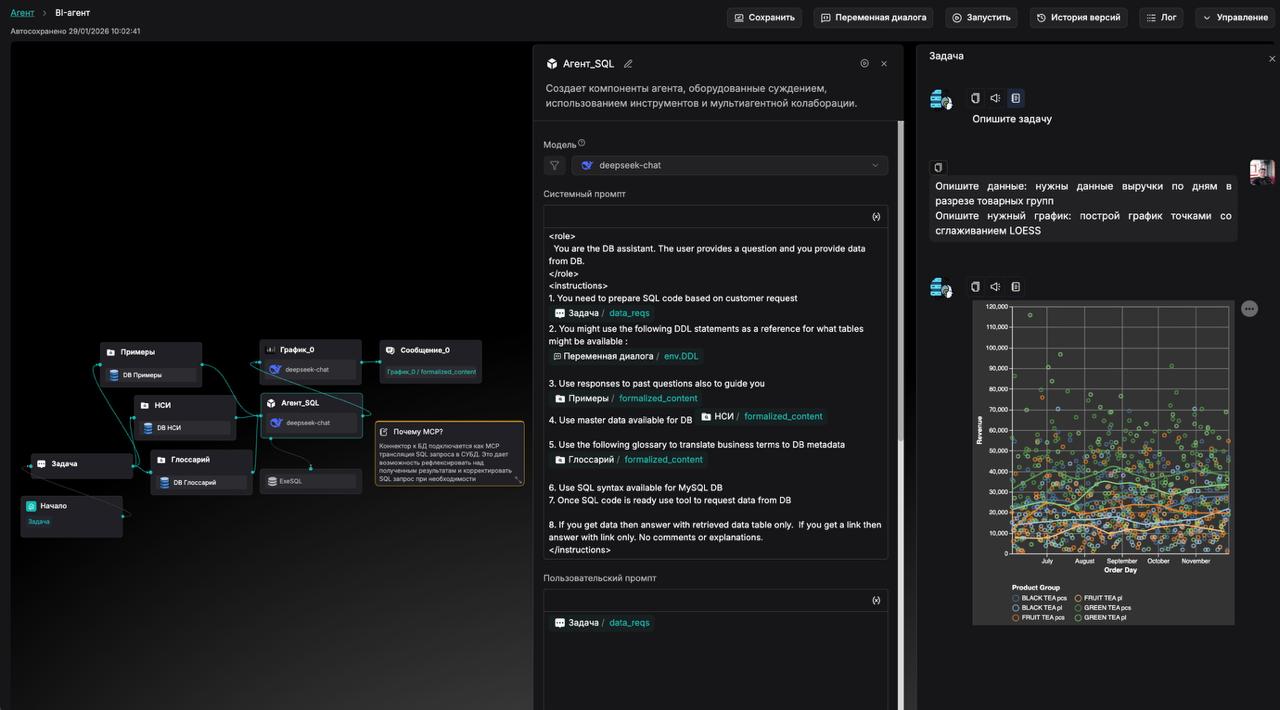
Описание функциональных блоков
Это модуль для загрузки и предварительной обработки исходных документов перед созданием базы знаний.
Поддержка множества форматов: Загрузка файлов в более чем 10 форматах, включая PDF, Word (DOCX), PowerPoint (PPTX), Excel (XLSX), текстовые файлы (TXT), Markdown (MD), изображения и другие.
Пакетная загрузка: Возможность загружать несколько файлов одновременно для удобства.
Извлечение текста: Автоматическое распознавание и извлечение текста из документов, включая текст с изображений (с помощью встроенного OCR).
Предварительный просмотр: Функция предварительного просмотра содержимого загруженного файла для проверки корректности извлечения текста.
Статус обработки: Отслеживание статуса каждого файла (например, “Загружен”, “Обрабатывается”, “Ошибка”, “Готово”).
Поддержка S3: Поддерживается загрузка файлов с объектного хранилища, совместимого с S3
Ключевой блок RAGu. Здесь создаются, настраиваются и наполняются семантические хранилища данных, которые используются для интеллектуального поиска и генерации ответов.
Создание и структуризация Баз Знаний (БЗ): Возможность создать множество независимых баз знаний для различных тематик, проектов или отделов. Организация документов в иерархические структуры для улучшения навигации и релевантности поиска.
Глубокое извлечение структуры информации:
- Извлечение ключевых слов: Автоматическая идентификация и извлечение наиболее значимых терминов и понятий из текста для улучшения семантического поиска и категоризации.
Автотегирование: Автоматическое присвоение документу и его фрагментам тегов на основе содержания, что позволяет осуществлять эффективную фильтрацию и группировку информации. Особенностью данной техники является возможность полу-автоматизированного контроля за результатом, а также отсутствие необходимости использования LLM т.к. работает только модель эмбеддинга.
Расширенная предобработка и обогащение данных:
- Генерация авто-вопросов: Для каждого семантического фрагмента текста (чанка) система автоматически генерирует список вероятных вопросов, на которые этот фрагмент отвечает, используя языковую модель (LLM). Это кардинально повышает точность извлечения релевантной информации, сопоставляя запрос пользователя не только с ответами, но и с вопросами.
- Генерация авто-ключевых слов: Использование LLM для автоматической генерации ключевых слов и синонимов из каждого чанка для коррекции ошибок и повышения точности ретриваля.
- Абстрактная рекурсивная обработка RAPTOR: Передовая техника рекурсивного summarize-and-index, которая строит древовидную структуру документа. Это позволяет системе понимать контекст на разных уровнях абстракции — от отдельных фактов до общих тем, — что значительно улучшает качество ответов на сложные, комплексные запросы.
- Построение графа знаний GraphRAG: Выявление и визуализация связей между различными сущностями, понятиями и фактами внутри документов. Это позволяет LLM понимать логические взаимосвязи и выполнять сложные выводы.
Управление метаданными:
- Ручное добавление метаданных: Возможность вручную добавлять метаданные к загруженным файлам для улучшения фильтрации и категоризации.
- Автоматическое извлечение метаданных: Автоматическое извлечение метаданных из документов с использованием LLM для структурирования информации.
- Управление на разных уровнях: Управление метаданными как на уровне всей базы знаний, так и для отдельных документов, что позволяет гибко настраивать фильтрацию и поиск.
Настройка процесса разбиения (Chunking):
- Умное разбиение: Использование семантического и структурного анализа (учитывая абзацы, заголовки, списки) для разделения документов на логически связанные фрагменты, а не просто по количеству символов.
- Родительско-дочернее разбиение (Parent-Child Chunking): Инновационный механизм, при котором документ сначала разбивается на крупные родительские чанки (сохраняющие семантическую целостность), которые затем подразделяются на более мелкие дочерние чанки для точного ретриваля. При поиске система сначала находит релевантные дочерние чанки, а затем автоматически извлекает связанные родительские чанки, обеспечивая высокую релевантность при сохранении полного контекста.
- Гибкие настройки: Возможность настроить размер чанков, перекрытие между ними и выбрать стратегию, оптимальную для конкретного типа документов.
Настройка контекстного окна для изображений и таблиц: Возможность задать размер контекстного окна специально для изображений и таблиц, что значительно улучшает обработку длинного контекста в RAG-системах при работе с визуальным контентом.
Выбор парсера PDF: Выбор визуальной модели для парсинга PDF-документов. Поддерживаются различные парсеры, такие как MinerU (для сложных научных документов с формулами и таблицами) и DeepDOC (для общего парсинга), что позволяет оптимизировать обработку различных типов PDF-файлов.
Настройка Page Rank: Механизм приоритизации информации из определенных баз знаний при поиске по нескольким источникам. Позволяет настроить пошаговую стратегию ретриваля, при которой чанки из баз знаний с более высоким Page Rank получают приоритет при ранжировании результатов. Особенно полезно, когда нужно приоритизировать информацию из определенных источников (например, новости 2024 года над новостями 2023 года).
Конвертация Excel в HTML (Excel2HTML): Автоматическое преобразование сложных Excel-таблиц в HTML-формат для улучшения их обработки и индексации. Это позволяет системе более эффективно работать со структурированными данными из таблиц.
Извлечение оглавления (Table of Contents): Автоматическое извлечение структуры документа (оглавления) для предоставления длинного контекста в RAG и улучшения качества ретриваля. Система использует LLM для генерации структуры документа и автоматически дополняет недостающий контекст при поиске на основе этой структуры.
Подключение источников данных (Data Sources): Возможность подключения внешних источников данных помимо прямой загрузки файлов. Поддерживаются более 20 различных источников, включая:
- Облачные хранилища: S3, Google Cloud Storage, Dropbox, Box, OCI Storage, R2
- Корпоративные платформы: Confluence, Jira, SharePoint, Slack, Teams, Notion
- Почтовые системы: Gmail, IMAP
- Системы управления проектами: Asana, Airtable, Zendesk
- Системы контроля версий: GitHub, GitLab, Bitbucket
- Образовательные платформы: Moodle
- Протоколы: WebDAV
Векторизация и индексация: Автоматическое создание векторных Embeddings для каждого фрагмента текста и его метаданных с последующим сохранением в векторной базе данных (например, ElasticSearch, OpenSearch и другие).
Мониторинг и тестирование:
- Мониторинг: Просмотр статистики и статуса обработки всех файлов в базе знаний (например, “обработан”, “ошибка”, “индексируется”).
- Тестирование качества: Встроенные инструменты для проверки эффективности базы знаний. Возможность запускать тестовые запросы, оценивать релевантность извлекаемых чанков и точность генерируемых ответов перед использованием в продакшене. Это позволяет непрерывно оценивать и улучшать качество поиска.
Интерфейс для взаимодействия с вашими базами знаний через естественный язык.
Выбор Базы Знаний: Перед началом диалога пользователь выбирает, с какой конкретной базой знаний он хочет взаимодействовать.
Диалоговый интерфейс: Удобный и интуитивно понятный чат, похожий на ChatGPT или другие современные мессенджеры.
Показ источников (Citation):
- Ключевая функция: После каждого ответа система отображает точные фрагменты текста из оригинальных документов, которые были использованы для генерации ответа.
- Верификация: Пользователь может кликнуть на источник и увидеть, из какого именно документа и раздела был взят этот фрагмент, что позволяет проверить достоверность ответа.
Настройка LLM: Возможность выбрать какую языковую модель использовать для генерации ответов (например, GPT-3.5, GPT-4, локальные модели через OpenAI API-совместимые провайдеры).
Глубокое исследование (Deep Research): Функция агентного рассуждения для глубокого анализа сложных вопросов. Активируется через переключатель “Reasoning” в настройках чата. Реализует многошаговый процесс исследования:
- Использует Tavily API для веб-поиска актуальной информации
- Автоматически генерирует план исследования с декомпозицией задачи на подзадачи
- Выполняет множественные поисковые запросы для сбора информации
- Извлекает и структурирует информацию из найденных источников
- Синтезирует комплексный ответ на основе собранных данных
- Отображает процесс рассуждения и найденные источники
Переменные (Variables): Возможность настройки переменных, которые используются вместе с системным промптом для LLM. Позволяет динамически настраивать поведение чата, персонализировать ответы и адаптировать систему под различные сценарии использования без изменения основной логики.
История диалогов: Сохранение истории чатов для дальнейшего использования и анализа.
AI Search — это режим одноразового AI-диалога (single-turn), предназначенный для быстрого получения ответов с отображением найденных источников. Отличается от полноценного чата отсутствием многошагового контекста и продвинутых RAG-стратегий.
Семантический (Векторный) Поиск: Поиск по смыслу, а не только по ключевым словам. Система находит фрагменты текста, которые семантически близки к смыслу запроса пользователя.
Гибридный Поиск: Комбинация семантического и поиска по ключевым словам (lexical, например, с использованием BM25) для максимальной релевантности результатов. Это позволяет находить информацию даже по точным названиям продуктов, кодам ошибок или редким терминам.
Системная модель по умолчанию: Использует системную LLM по умолчанию для генерации ответов, что упрощает процесс использования.
Отображение найденных чанков: После генерации ответа система отображает все найденные фрагменты текста (чанки) под ответом, отсортированные по убыванию релевантности (похожести). Это позволяет пользователю самостоятельно оценить качество ретриваля и проверить источники.
Без продвинутых RAG-стратегий: В отличие от полноценного чата, AI Search не использует такие продвинутые техники, как граф знаний (knowledge graph), авто-ключевые слова (auto-keyword) или авто-вопросы (auto-question), что делает его более быстрым и простым инструментом.
Инструмент отладки: Особенно полезен при настройке чат-ассистента или агента для проверки корректности работы модели и стратегии ретриваля перед использованием в полноценном диалоге.
Быстрый доступ к контексту: Просмотр не только самого фрагмента, но и его окружения в оригинальном документе для лучшего понимания контекста.
Мощная среда визуального программирования (Low-Code/No-Code) для создания сложных AI-агентов, способных автоматизировать многошаговые workflows и интегрироваться с внешними системами. Агенты комбинируют возможности LLM с инструментами для выполнения конкретных задач.
- Базовые конструктивные блоки (ноды):
- Begin (Начало): Точка входа в workflow агента, может включать приветственное сообщение (prologue) и настройку режима работы (conversational или нет).
- Agent (Агент): Основной блок для взаимодействия с языковыми моделями с поддержкой инструментов (tools). Может выполнять многораундовые диалоги, вызывать инструменты и взаимодействовать с MCP (Model Context Protocol).
- Retrieval (Поиск): Векторный и гибридный поиск по подключенным базам знаний RAGu. Поддерживает настройку весов ключевого и векторного поиска, фильтрацию по метаданным, использование графа знаний и ранжирование результатов.
- Categorize (Категоризация): Отнесение текста к предопределенным категориям с использованием LLM (например, “позитивный отзыв”, “жалоба”, “запрос информации”). Поддерживает маршрутизацию на основе категории.
- KeywordExtract (Извлечение ключевых слов): Автоматическое выделение основных терминов из текста для улучшения поиска.
- Generate (Генерация): Создание текстового контента на основе промпта и контекста с использованием LLM.
- Message (Сообщение): Блок для отправки статических или динамических сообщений. Может содержать несколько вариантов ответа, один из которых выбирается случайным образом.
- Condition/If-Else (Условие): Логическое ветвление workflow в зависимости от результата предыдущего шага (например, “если тональность негативная, отправить ноду ‘Эскалация’, иначе ‘Благодарность’”).
- Loop/While (Цикл): Многократное выполнение цепочки действий до достижения определенного условия (например, обработка каждого элемента в списке).
- UserFillUp (Ожидание): Блок для получения дополнительной информации от пользователя во время выполнения агента.
- Интеграционные блоки (API и сторонние сервисы):
- Google Search: Поиск актуальной информации в интернете.
- Yahoo Finance: Получение данных о котировках акций и финансовых новостях.
- Wikipedia: Извлечение структурированной информации из энциклопедии.
- Email: Отправка и получение писем по протоколам SMTP/IMAP.
- Webhook: Взаимодействие с внешними API и системами.
- Эксклюзивные и специализированные блоки:
График (Chart): Собственный блок для построения сложной визуализации данных (диаграммы, графики) на основе обработанной текстовой или структурированной информации. Позволяет реализовать сценарий BI bot, предназначенный для ad-hoc анализа без навыков программирования.Yandex Search: Передовой поиск, оптимизированный для русского языка и рунета, обеспечивающий высокорелевантные результаты для локальных запросов.ExeSQL: Уникальный блок для безопасного исполнения SQL-запросов к подключенным базам данных. Автоматически кеширует результаты для ускорения последующих выполнений и снижения нагрузки на БД.
- Управление жизненным циклом агентов:
- Визуальный конструктор: Drag-and-drop интерфейс для проектирования сложных цепочек действий (workflows) без написания кода. Поддерживает создание сложных графов с условными переходами и параллельными ветками.
- Управление версиями: Система контроля версий для каждого агента. Возможность сохранять, коммитить изменения, просматривать историю и откатываться к предыдущим стабильным версиям.
- Импорт/Экспорт: Возможность выгрузить конфигурацию любого агента в виде JSON-файла для резервного копирования, переноса между инстансами RAGu или совместной разработки. Аналогично, можно загрузить готового агента из JSON-файла.
- Шаблоны агентов: Доступ к библиотеке готовых шаблонов агентов для различных сценариев (customer service, deep research, general chatbot и др.), которые можно использовать как основу для собственных решений.
- Встраивание через iframe: Возможность встроить интерфейс конкретного агента через iframe в корпоративные порталы, веб-сайты или другие приложения.
Модуль памяти обеспечивает сохранение и эффективное использование информации о прошлых взаимодействиях для улучшения качества диалогов и персонализации ответов.
- Назначение:
- Хранение взаимодействий: Модуль памяти сохраняет все взаимодействия, включая разговоры во время работы агента. Хранит сырые логи разговоров (что сказал пользователь и что ответил AI), а также дополнительную информацию, созданную во время чата (резюме, заметки).
- Обеспечение непрерывности: Обеспечивает плавный переход от одного разговора к другому, сохраняя контекст предыдущих диалогов.
- Персонализация: Сохранение личных деталей пользователя (предпочтения, история взаимодействий) для персонализации ответов.
- Обучение на опыте: Позволяет системе обучаться на основе прошлых взаимодействий и использовать этот опыт для улучшения будущих ответов.
- Типы памяти:
- Raw (Сырая память): Сохранение исходных, неизмененных диалогов в их первоначальном виде. Представляет собой точную запись всех сообщений пользователя и ответов системы.
- Semantic (Семантическая память): Структурированная семантическая память, содержащая извлеченные факты, знания и концепции в абстрактной форме. Позволяет системе быстро находить релевантную информацию без поиска по всему диалогу.
- Episodic (Эпизодическая память): Память о конкретных событиях и контексте взаимодействий. Включает информацию о том, когда и в каких обстоятельствах происходили определенные диалоги, что помогает восстановить полный контекст.
- Procedural (Процедурная память): Память о процедурах, процессах и шаблонах взаимодействий. Хранит информацию о том, как система решала определенные типы задач в прошлом.
- Типы хранения:
- Table (Табличное): Хранение памяти в структурированном табличном формате, оптимизированном для быстрого поиска и фильтрации по различным атрибутам.
- Graph (Графовое): Хранение памяти в виде графа знаний, где связи между различными элементами памяти представлены как ребра графа. Позволяет находить сложные взаимосвязи и выполнять более глубокий анализ.
- Управление памятью:
- Настройка размера памяти: Возможность задать максимальный размер памяти (по умолчанию 5MB), что позволяет контролировать объем хранимой информации.
- Политики забывания: Настройка стратегии управления переполнением памяти:
- FIFO (First In, First Out): Удаление самых старых записей при достижении лимита.
- LRU (Least Recently Used): Удаление наименее используемых записей, сохраняя наиболее релевантную информацию.
- Настройка промптов: Возможность настроить системный и пользовательский промпты для обработки памяти, что позволяет кастомизировать то, как система использует сохраненную информацию.
- Выбор моделей: Настройка моделей эмбеддингов и LLM, используемых для обработки и извлечения информации из памяти.
- Интеграция с агентами и чатом:
- Автоматическое использование памяти во время диалогов для предоставления контекста из прошлых взаимодействий.
- Поддержка персональных и командных режимов работы памяти (permissions: “me” или “team”).
- Возможность привязки памяти к конкретным агентам для сохранения контекста их работы.
Центр управления ресурсами, моделями и доступом в системе.
- Центр управления моделями (Model Hub):
- Управление LLM: Подключение и конфигурация языковых моделей от различных провайдеров (OpenAI, Anthropic, локальные модели).
- Модели эмбеддингов: Выбор и настройка моделей для создания векторных представлений текста.
- Специализированные модели: Интеграция моделей для обработки изображений и речи.
- Поддержка провайдеров:
- Локальные LLM: Работа с открытыми моделями через Ollama, vLLM и другие совместимые серверы.
- Интеграция с
YandexGPT: Поддержка моделейYandexGPT.
- Поддержка Model Context Protocol (MCP):
- Совместимость с протоколом MCP для подключения внешних инструментов и источников данных.
- Совместимость с протоколом MCP для подключения внешних инструментов и источников данных.
- Возможности интеграции:
- RESTful API: API для интеграции чат-интерфейсов и поиска во внешние системы.
- Встраивание через iframe: Возможность встроить интерфейсы RAGu в корпоративные порталы.
- Управление доступом (RBAC):
- Гибкое управление правами: Настройка прав для пользователей и групп.
- Доступ к базам знаний: Ограничение видимости и использования конкретных баз знаний.
- Доступ к агентам: Разграничение прав на просмотр, запуск и редактирование агентов.
- Мониторинг:
- Статус компонентов системы: Контроль работоспособности ключевых сервисов (векторная БД, кэш, inference-серверы моделей).
- Мониторинг задач обработки: Отслеживание статуса и прогресса фоновых задач по пакетной обработке документов (загрузка, индексация, обновление баз знаний).
Мы предлагаем
Внедрение
Подбор локальных и публичных LLM под нужды заказчика Развертывание на стороне заказчика
Обучение
Методическое и практическое обучение по работе с LLM, VLM
Доработки
Адаптация и до- обучение моделей искусственного интеллекта, интеграция в бизнес-процессы и продуктивный контур